
TL;DR — Was du nach diesem Artikel hast
- Vollständiger Bauplan einer vollautomatischen YouTube-Pipeline für deutsche KI-Erklärvideos: News-Scraping → Script → Visuals → Voiceover → Final-MP4.
- Realer Stack: Python 3.12, Claude API, Replicate (Flux Schnell), Manim, ElevenLabs, ffmpeg, Whisper — mit Code zum 1:1 Übernehmen.
- Lokales GPU-Rendering auf AMD Radeon RX 7900 XTX hat viermal das System gecrasht — die ganze ROCm-Memory-Leak-Geschichte.
- Lösung: Cloud-API (Replicate Flux Schnell) für T2I + ffmpeg Ken-Burns-Pan statt lokalem I2V — stabil, ~$0.91 pro Video.
- Production-Run: ein 4:30-Minuten-Video in ~25 Minuten fertig, inklusive Untertitel und BGM.
Wenn du einen faceless YouTube Channel automatisieren willst, gibt es 2026 zwei Wege: All-in-One-SaaS-Tools mieten oder eine eigene Pipeline bauen. Ich habe mich für letzteres entschieden — und in zwei Tagen alles erlebt, was beim faceless YouTube Channel automatisieren schiefgehen kann. Vier System-Crashes, ein Pivot von lokalem auf Cloud-Rendering, und am Ende eine Pipeline, die in 25 Minuten ein fertiges Video produziert.
Dieser Artikel ist die ehrliche Build-Doku. Keine Marketing-Story über „wie einfach es ist”. Code 1:1 wie er produktiv läuft, alle Sackgassen mit Screenshots, und am Ende der Stack der wirklich funktioniert.
Warum überhaupt eine eigene Pipeline?
Marktlage 2026: Faceless YouTube-Channels mit KI sind etabliert. Tools wie FluxNote, Pictory, Clippie und AutoClips bieten All-in-One-Lösungen ab $19–39/Monat. Du gibst ein Topic ein, das Tool spuckt ein Video aus.
Warum trotzdem selber bauen?
Volle Kontrolle über Stil und Niche. Mein Channel christianohle macht deutsche KI-Erklärvideos im 3Blue1Brown-Stil mit Manim-Animationen. Kein All-in-One-Tool kann das.
Manim-Integration. Mathematische und konzeptionelle Animationen sind der Differenzierer im DACH-KI-Niche. Während alle anderen Stock-Footage und KI-Bilder reincutten, kannst du mit Manim Vektorräume, ELO-Kurven oder Reward-Funktionen sauber visualisieren.
Skalierbar gegen Null Grenzkosten. Eine eigene Pipeline kostet pro Video nur die API-Calls. Bei 100 Videos pro Monat sind das ~$150 statt $390+ bei SaaS.
Lerneffekt. Ich verstehe meinen Stack komplett. Wenn was kaputt geht, kann ich es fixen. Bei einem Black-Box-SaaS bist du auf den Vendor angewiesen.
Trade-off: Setup-Zeit. Was ich anfangs auf 90 Minuten geschätzt hatte, wurden zwei Tage. Davon will ich erzählen.
Der ursprüngliche Plan
Hardware:
- AMD Radeon RX 7900 XTX (24 GB VRAM)
- 32 GB RAM
- Windows 11
Geplanter Stack:
- Python 3.12 für Pipeline-Code
- Claude Opus 4.7 für Script-Generation
- Manim für mathematische Animationen
- ComfyUI mit Wan 2.2 14B für lokales Image-to-Video Rendering
- RealVisXL V5.0 für T2I Hero-Shots
- ElevenLabs für deutsche TTS
- ffmpeg + Whisper für Assembly
Die Idee war: alles lokal rendern, kein Cloud-Lock-In, volle Datenhoheit. Eine 7900 XTX mit 24 GB VRAM ist 2026 hardwareseitig mehr als genug für T2I- und I2V-Workflows.
Spoiler: Mit AMD ROCm auf Windows funktioniert das in 2026 immer noch nicht zuverlässig. Hier die Story.
Die Crash-Saga — warum lokales Video-Rendering auf AMD scheiterte
Tag 1, 14:00 Uhr — Setup läuft, ComfyUI erkennt die GPU
ComfyUI Desktop installiert, ROCm-PyTorch-Build ausgewählt. Auf den ersten Blick sieht alles gut aus:
Devices: cuda:0 AMD Radeon RX 7900 XTX : native
VRAM Total: 23.98 GB
PyTorch: 2.9.1+rocmsdk20260116Native ROCm-Build, kein ZLUDA-Hack. PyTorch erkennt die GPU als cuda:0 weil ROCm sich als CUDA-kompatibel ausgibt.
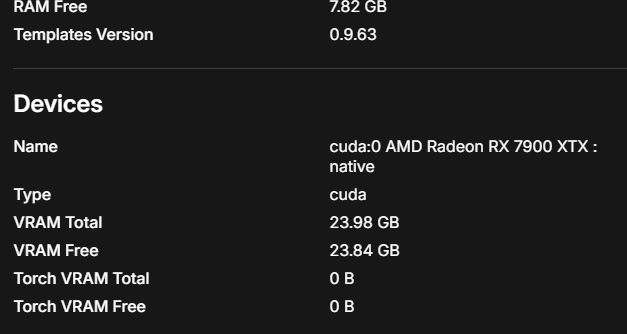 ComfyUI Desktop nach frischer Installation — die 7900 XTX wird korrekt erkannt, ROCm 7.1 läuft.
ComfyUI Desktop nach frischer Installation — die 7900 XTX wird korrekt erkannt, ROCm 7.1 läuft.
Modelle gedownloaded (~60 GB):
- RealVisXL V5.0 für T2I
- LTX-Video 2B für I2V
- Wan 2.2 14B I2V (High + Low Noise Expert) für hochwertiges I2V
Tag 1, 16:30 Uhr — Wan 2.2 läuft sich tot
Erster Test mit Wan 2.2 14B I2V Template. Drachenkrieger-Demo-Bild reingeladen, Run.
Nach 16 Minuten: Total bei 0%, Render-Stage bei 30%.
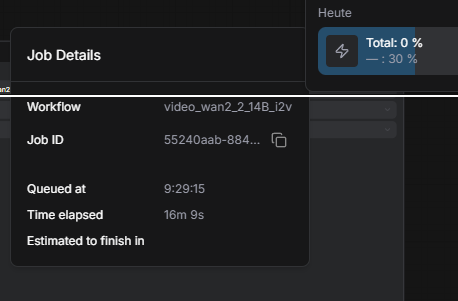 Wan 2.2 nach 16 Minuten immer noch bei 30% einer einzigen Stage. Hochgerechnet 50+ Minuten pro 5-Sekunden-Clip.
Wan 2.2 nach 16 Minuten immer noch bei 30% einer einzigen Stage. Hochgerechnet 50+ Minuten pro 5-Sekunden-Clip.
Bei der Geschwindigkeit hochgerechnet wären das 50+ Minuten pro 5-Sekunden-Clip. Bei einer Pipeline mit 2 Comfy-Szenen pro Video und 3 Videos pro Woche wäre das fast 5 Stunden pure Render-Zeit. Praxistauglich = Nein.
Bekannte Probleme bei AMD ROCm + Wan 2.2:
- ROCm Kernel-Recompilation zwischen den zwei Diffusion-Modellen kostet jedes Mal Sekunden
- fp8-Quantisierung auf AMD ist nicht so optimiert wie auf NVIDIA
- Lightning LoRA-Loading zwischen Stages dauert auf AMD länger
Job gestoppt. Switch auf LTX-Video.
Tag 1, 18:45 Uhr — Erster System-Crash
LTX-Video lief beim ersten Test in 76 Sekunden durch. Erfolg, dachte ich.
Aber: Output zeigt nicht den Drachenkrieger, sondern eine Winterszene. Grund: strength=0.15 im LTX-Workflow ist sehr niedrig. LTX nimmt das Input-Bild nur als lose Inspiration und halluziniert frei.
Fix: strength=0.75 für Image-treues Animieren.
Zweiter Test-Run. Mitten im Render: kompletter System-Hänger. Maus reagiert nicht, Bildschirm eingefroren.
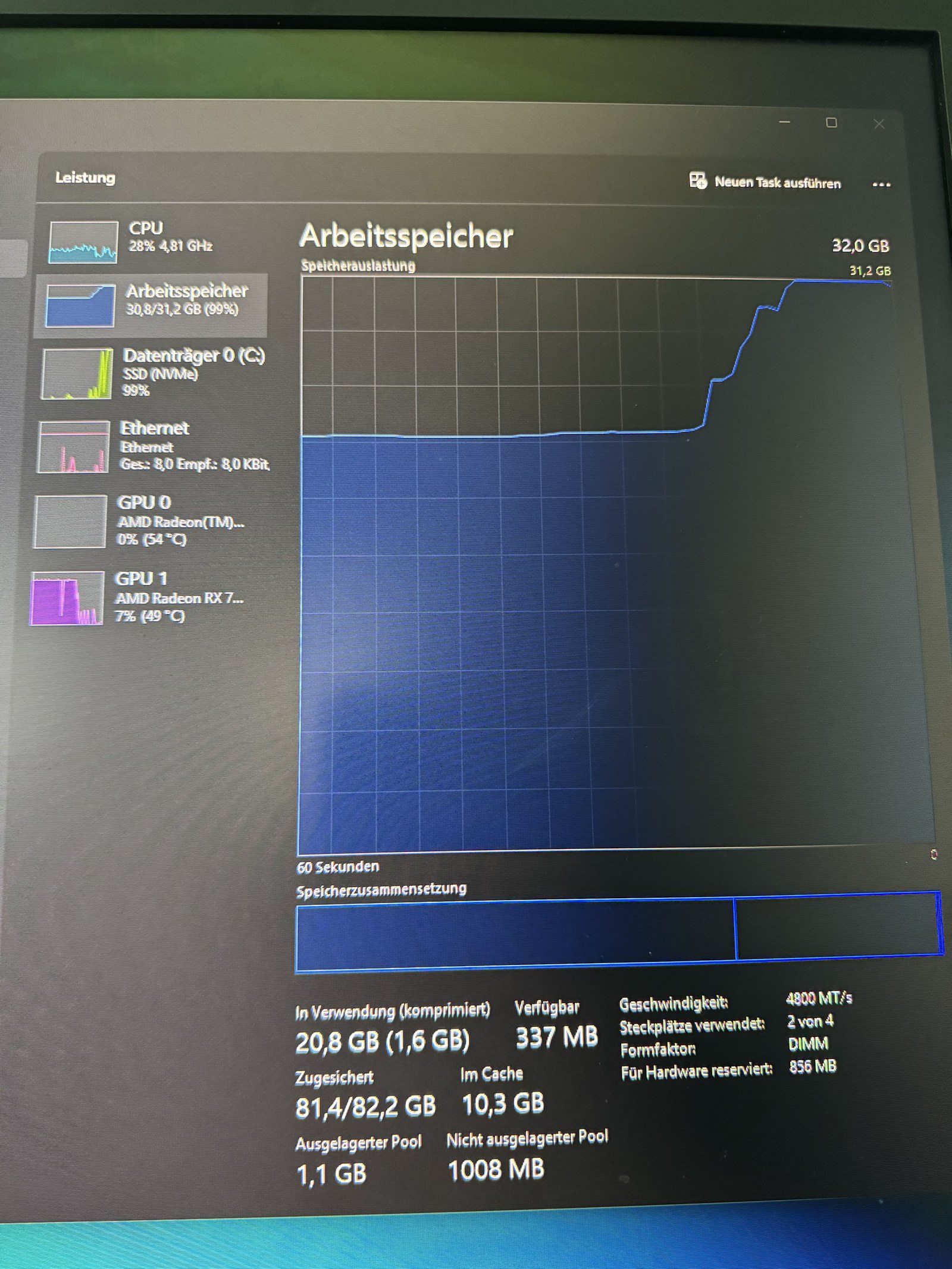 Vom Handy fotografiert: Task Manager zeigt 30,8 von 31,2 GB RAM belegt, Datenträger 99%. Das System hat keine Atemluft mehr.
Vom Handy fotografiert: Task Manager zeigt 30,8 von 31,2 GB RAM belegt, Datenträger 99%. Das System hat keine Atemluft mehr.
Diagnose: Wan-Modelle waren noch im VRAM, plus shared GPU memory hatte 3,6 GB ins System-RAM gespillt. ROCm gibt RAM zwischen Runs nicht sauber frei. Hard-Reboot.
Tag 2, 10:00 Uhr — Refiner-Bug bei T2I
Nach dem Reboot wollte ich erst mal isoliert T2I testen. RealVisXL allein, kein I2V. Output:
 T2I-Output mit Noise-Mantle. Das Bild sieht aus wie eine Aquarell-Skizze, nicht wie ein scharfes Foto. Ursache: KSampler-Default für 2-Stage-Workflows mit Refiner.
T2I-Output mit Noise-Mantle. Das Bild sieht aus wie eine Aquarell-Skizze, nicht wie ein scharfes Foto. Ursache: KSampler-Default für 2-Stage-Workflows mit Refiner.
Diagnose: das „SDXL Simple”-Template ist auf 2-Stage-Inference ausgelegt (Base + Refiner). Ich hatte den Refiner gelöscht, aber im KSampler stand:
"return_with_leftover_noise": "enable",
"end_at_step": 20Das heißt: Sampler stoppt bei Step 20 von 25 und gibt Latent mit Restnoise raus, weil er denkt der Refiner kommt noch. Ohne Refiner = noisy Output.
Lesson: Wenn ein Template aus mehreren Stages besteht und du eine Stage löschst, sind die KSampler-Defaults nicht für Single-Stage gedacht. Lieber von Grund auf bauen als Refiner-Templates „vereinfachen”.
Fix: Sauberen 7-Node Minimal-Workflow von Hand gebaut — Load Checkpoint, 2× CLIP Text Encode, Empty Latent Image, KSampler (kein Advanced!), VAE Decode, Save Image. KSampler statt KSamplerAdvanced, dpmpp_2m + karras, cfg=5.
Resultat:
 Knackscharfes London-Office bei Blue Hour mit RealVisXL V5.0 und sauberem Workflow. Endlich.
Knackscharfes London-Office bei Blue Hour mit RealVisXL V5.0 und sauberem Workflow. Endlich.
T2I funktioniert jetzt. Aber I2V steht noch aus.
Tag 2, 14:00 Uhr — Crash 2, 3, 4
Mit dem sauberen Workflow nochmal Versuch: T2I → I2V Pipeline-Lauf.
 Der T2I-Output für die Server-Raum-Szene — atemberaubend scharf, exakt der Sci-Fi-Look den ich wollte.
Der T2I-Output für die Server-Raum-Szene — atemberaubend scharf, exakt der Sci-Fi-Look den ich wollte.
LTX produziert qualitativ sehr gute Outputs. ABER: nach jedem Render-Zyklus crasht das System.
Versuche zur Rettung:
- Auto-Restart-Workaround: ComfyUI-Prozess nach jedem Render killen und neustarten. Crash beim zweiten Render.
- Niedrigere Auflösung: 512×288 statt 768×432. Crash früher als vorher.
- Nur T2I, kein I2V: Sogar das crasht jetzt, akkumulierter Memory-Druck.
Vier System-Crashes in zwei Tagen. Jedes Mal Hard-Reboot.
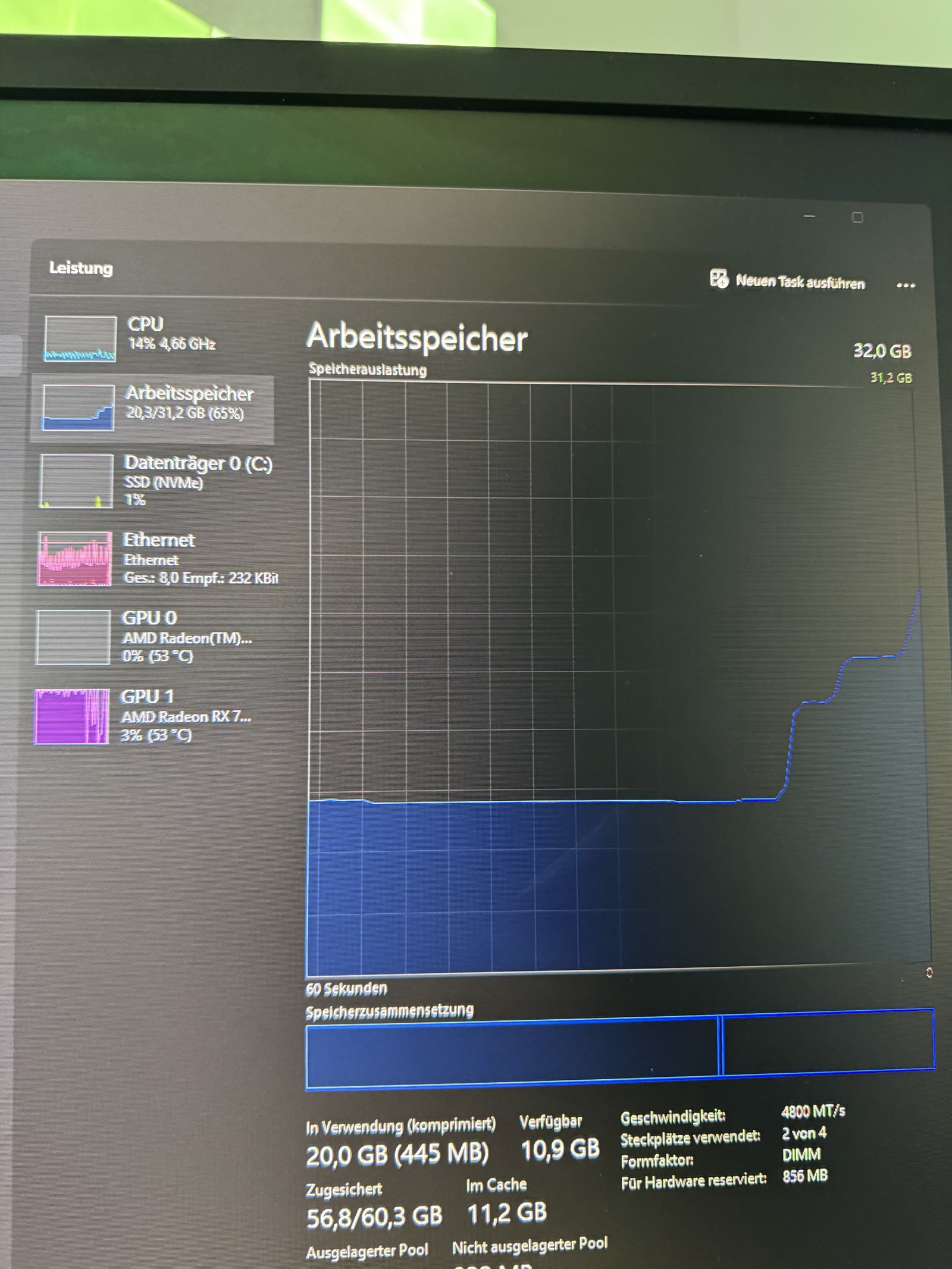 Crash Nr. 3. Speicherauslastung 65% — aber „Zugesichert” 56,8 von 60,3 GB. Klassischer ROCm-Memory-Leak.
Crash Nr. 3. Speicherauslastung 65% — aber „Zugesichert” 56,8 von 60,3 GB. Klassischer ROCm-Memory-Leak.
Recherche bestätigt: bekanntes Problem. Zitat aus dem ComfyUI GitHub:
„I was happy to saw this, but after clean install on AMD rocm drivers, ComfyUI Desktop and Portable, every Workflow crashs.”
Andere Reports: HIP errors, illegal memory access, instant crashes after Generate-click. Alles dasselbe Pattern.
Stand 2026: AMD ROCm auf Windows ist für T2I in einfachen Workflows brauchbar. Für I2V mit Memory-Heavy-Models wie Wan 2.2 oder LTX in einer automatisierten Pipeline ist es nicht produktionsreif. Wer eine KI Video Pipeline bauen will, die 24/7 zuverlässig durchläuft, kann sich auf ComfyUI AMD ROCm unter Windows derzeit nicht verlassen.
Zeit für einen Pivot.
Der Pivot — Cloud-API statt lokales Rendering
Die Entscheidung: lokales GPU-Rendering aufgeben, Cloud-API nutzen.
Optionen:
- Replicate (Flux Schnell, Flux Dev, SDXL): einfache API, $0.003–$0.025 pro Bild
- Fal.ai (Flux): schnellste Inference, queue-basiert
- Together AI (Flux): günstigste Pricing für Flux
Bei meinem Volumen (24 Bilder/Monat) sind die Kosten vernachlässigbar — unter $1/Monat selbst bei Flux Dev. Wahl nach Stabilität, nicht Preis.
Entscheidung: Replicate Flux Schnell.
- $0.003 pro 1024×1024 Bild
- ~3 Sekunden pro Render
- Stabile API mit Python-SDK
- Keine Cold-Start-Probleme bei populären Modellen
Für die Bewegung im Video: kein I2V mehr. Stattdessen ffmpeg Ken-Burns-Pan über das generierte Standbild. Das ist wie wenn du in iMovie ein Foto reinziehst und einen subtilen Zoom oder Pan drauf legst. Sieht professionell aus, kostet keine GPU-Zyklen, crasht nichts.
Inspiration: 3Blue1Brown nutzt fast nur Standbilder mit subtilen Bewegungen. Für KI-Erklärvideos ist das absolut tragfähig.
Die finale Architektur
Pipeline-Übersicht
Eine Pipeline-Stage pro Modul. Jede Stage hat einen klaren Input und Output:
News-Scraper → JSONL mit Headline-Kandidaten
Topic-Selector → 1 Topic-JSON pro Video
Script-Generator → Scene-JSON mit 12-15 Szenen, Visual-Types
Visual-Renderer → Pro Szene ein MP4
Voice-Synthesizer → Pro Szene ein MP3
Assembly → Final-MP4 mit BGM und SRT-CaptionsVisual-Types:
manim: mathematische/strukturelle Animationen via Manimslide: HTML-Templates mit Bullets, gerendert via Playwrightcomfy: Hero-Shots via Replicate Flux Schnell + Ken-Burnsstock: Pexels-Footage als Fallbacktitle_card: große Titel-Slide
Parallelisierung: CPU/API-Visuals parallel (Manim, Slide, Replicate API), Voice seriell (rate-limit-bedingt).
Module-Übersicht
Die Pipeline ist in fokussierte Module aufgeteilt — jedes mit klar definierter Aufgabe und einem eigenen Verantwortungsbereich:
- Scraper — News aus RSS, Hacker News, arXiv, Reddit einsammeln
- Script-Module — Claude Haiku rankt Topics, Claude Opus generiert das Szenen-JSON, Pydantic validiert das Schema
- Visual-Module — Manim-Animationen via Claude-generated Code, HTML-Slides via Playwright, Stock-Clips via Pexels-API, atmosphärische Hero-Bilder via Replicate Flux Schnell mit Ken-Burns-Pan
- Voice-Modul — ElevenLabs Turbo v2.5 für deutsche Synthese
- Assembly-Modul — ffmpeg-Merge, Whisper-Subtitles, BGM mit Sidechain-Ducking
- Pipeline-Orchestrator — koordiniert alle Module, parallel/seriell, mit Cache- und Fallback-Logik
Der Replicate-Renderer (Cloud-T2I + Ken-Burns)
Der Comfy-Renderer (Name historisch — „comfy” für ComfyUI) ruft inhaltlich die Replicate API auf. Hier der Code, der produktiv läuft:
"""ComfyUI-Adapter ersetzt durch Replicate API.
PRODUCTION VERSION: T2I via Replicate Flux Schnell + Ken-Burns via ffmpeg.
Hintergrund: ComfyUI auf AMD ROCm Windows verursachte wiederholt System-Crashes
(VRAM-/RAM-Memory-Leaks, sowohl bei T2I als auch bei I2V). Stattdessen jetzt:
- T2I via Replicate Cloud API (Flux Schnell, ~3s/Bild, ~$0.003/Bild)
- Ken-Burns Pan via ffmpeg lokal (kein GPU-Stress)
"""
from __future__ import annotations
import os
import random
import subprocess
from pathlib import Path
import requests
from rich.console import Console
from config.settings import ASSETS_DIR
console = Console()
REPLICATE_API_TOKEN = os.getenv("REPLICATE_API_TOKEN")
REPLICATE_MODEL = "black-forest-labs/flux-schnell"
# ============================================================
# T2I via Replicate Flux Schnell
# ============================================================
def render_t2i(prompt: str, output_dir: Path, scene_id: int,
negative: str = "", width: int = 1280, height: int = 720) -> Path:
"""Text-zu-Bild via Replicate Flux Schnell."""
if not REPLICATE_API_TOKEN:
raise RuntimeError(
"REPLICATE_API_TOKEN nicht gesetzt. In .env eintragen."
)
output_dir.mkdir(parents=True, exist_ok=True)
aspect = _aspect_ratio(width, height)
console.print(f"[cyan]→ Replicate Flux Schnell: {prompt[:80]}…[/cyan]")
import replicate
client = replicate.Client(api_token=REPLICATE_API_TOKEN)
output = client.run(
REPLICATE_MODEL,
input={
"prompt": prompt,
"aspect_ratio": aspect,
"num_outputs": 1,
"num_inference_steps": 4,
"output_format": "png",
"output_quality": 95,
},
)
image_url = output[0] if isinstance(output, list) else output
if hasattr(image_url, "url"):
url = image_url.url() if callable(image_url.url) else image_url.url
else:
url = str(image_url)
target = output_dir / f"scene_{scene_id:03d}_keyframe.png"
r = requests.get(url, timeout=60)
r.raise_for_status()
target.write_bytes(r.content)
console.print(f"[green]✓ T2I keyframe scene_{scene_id:03d}[/green]")
return target
def _aspect_ratio(width: int, height: int) -> str:
"""Mappe Pixel-Auflösung auf Flux Schnell aspect_ratio strings."""
ratio = width / height
candidates = {
"1:1": 1.0, "16:9": 16/9, "9:16": 9/16,
"4:3": 4/3, "3:4": 3/4, "21:9": 21/9, "3:2": 3/2, "2:3": 2/3,
}
best = min(candidates.items(), key=lambda kv: abs(kv[1] - ratio))
return best[0]
# ============================================================
# Ken-Burns-Pan via ffmpeg
# ============================================================
KEN_BURNS_MODES = ["zoom_in", "zoom_out", "pan_left", "pan_right", "pan_up", "drift_diag"]
def _build_kenburns_filter(mode: str, duration_sec: float, fps: int = 30,
src_w: int = 1280, src_h: int = 720,
dst_w: int = 1920, dst_h: int = 1080) -> str:
total_frames = max(2, int(round(duration_sec * fps)))
upscale = src_w * 4
upscale_h = src_h * 4
if mode == "zoom_in":
zoom = "zoom='min(zoom+0.0015,1.20)'"
x = "x='iw/2-(iw/zoom/2)'"
y = "y='ih/2-(ih/zoom/2)'"
elif mode == "zoom_out":
zoom = "zoom='if(lte(zoom,1.0),1.20,max(1.001,zoom-0.0015))'"
x = "x='iw/2-(iw/zoom/2)'"
y = "y='ih/2-(ih/zoom/2)'"
elif mode == "pan_left":
zoom = "zoom='1.15'"
x = f"x='iw-iw/zoom-(on/{total_frames})*(iw-iw/zoom)'"
y = "y='ih/2-(ih/zoom/2)'"
elif mode == "pan_right":
zoom = "zoom='1.15'"
x = f"x='(on/{total_frames})*(iw-iw/zoom)'"
y = "y='ih/2-(ih/zoom/2)'"
elif mode == "pan_up":
zoom = "zoom='1.15'"
x = "x='iw/2-(iw/zoom/2)'"
y = f"y='ih-ih/zoom-(on/{total_frames})*(ih-ih/zoom)'"
elif mode == "drift_diag":
zoom = "zoom='min(zoom+0.0008,1.12)'"
x = f"x='(on/{total_frames})*(iw-iw/zoom)'"
y = f"y='(on/{total_frames})*(ih-ih/zoom)'"
else:
zoom = "zoom='min(zoom+0.0012,1.15)'"
x = "x='iw/2-(iw/zoom/2)'"
y = "y='ih/2-(ih/zoom/2)'"
return (
f"scale={upscale}:{upscale_h}:flags=lanczos,"
f"zoompan={zoom}:{x}:{y}:d={total_frames}:s={dst_w}x{dst_h}:fps={fps},"
f"format=yuv420p"
)
def render_kenburns(keyframe: Path, duration_sec: float,
output_dir: Path, scene_id: int,
mode: str | None = None) -> Path:
"""Ken-Burns-Pan über Standbild via ffmpeg."""
output_dir.mkdir(parents=True, exist_ok=True)
if mode is None:
rng = random.Random(scene_id * 7919 + 11)
mode = rng.choice(KEN_BURNS_MODES)
from PIL import Image
with Image.open(keyframe) as img:
src_w, src_h = img.size
filter_str = _build_kenburns_filter(
mode=mode, duration_sec=duration_sec, fps=30,
src_w=src_w, src_h=src_h, dst_w=1920, dst_h=1080,
)
target = output_dir / f"scene_{scene_id:03d}.mp4"
cmd = [
"ffmpeg", "-y", "-loop", "1", "-i", str(keyframe),
"-vf", filter_str,
"-t", f"{duration_sec:.2f}",
"-r", "30", "-an",
"-c:v", "libx264", "-preset", "veryfast", "-crf", "20",
str(target),
]
proc = subprocess.run(cmd, capture_output=True, text=True)
if proc.returncode != 0:
raise RuntimeError(f"ffmpeg ken-burns failed: {proc.stderr[-1500:]}")
console.print(f"[green]✓ Ken-Burns ({mode}) scene_{scene_id:03d}.mp4[/green]")
return target
def render(visual_prompt: str, motion_hint: str | None, duration_sec: float,
output_dir: Path, scene_id: int) -> Path:
"""End-to-end: T2I (Replicate Flux Schnell) → Ken-Burns (ffmpeg)."""
keyframe = render_t2i(visual_prompt, output_dir, scene_id,
width=1280, height=720)
return render_kenburns(keyframe, duration_sec, output_dir, scene_id)Erklärung der Hauptfunktionen:
render_t2i() ruft Replicate Flux Schnell mit dem Prompt auf, lädt das resultierende Bild herunter und speichert es als scene_NNN_keyframe.png. Das ist das Replicate API Tutorial in seiner kompakten Form: Token aus .env, client.run() mit Modell und Input, Bild von der returnten URL ziehen.
render_kenburns() baut einen ffmpeg zoompan-Filter mit einem von 6 Modi (zoom_in, pan_left, drift_diag, etc.). Pro Scene-ID wird deterministisch ein Modus gewählt, damit aufeinanderfolgende Hero-Shots unterschiedlich wirken. Der scale=…:lanczos-Vorpass hochskaliert das Bild um Faktor 4 — sonst rendert ffmpegs zoompan matschig, weil es intern auf der Originalauflösung samplet.
render() ist die Public-API: T2I + Ken-Burns als End-to-End. Render-Zeit pro Comfy-Szene: ~30 Sekunden (3s Replicate + 2s Download + 10s ffmpeg + Overhead).
Der Manim-Renderer (Claude generiert Code)
Statt Manim-Code per Hand zu schreiben, lasse ich Claude den Code für jede Szene generieren — basierend auf dem visual_prompt aus dem Script-JSON. Das ist der Schritt, der Manim Erklärvideos wirklich skalierbar macht: man muss nicht für jede Animation Python-Code schreiben, sondern beschreibt nur, was visualisiert werden soll.
"""Manim-Renderer: Claude generiert Manim-Code, dann lokales Render via subprocess.
WICHTIG: max_tokens=8000 (nicht 3000!) damit komplexe Manim-Szenen vollständig
generiert werden. Mit 3000 Tokens kommen Syntax-Fehler durch abgeschnittenen Code.
"""
from pathlib import Path
import subprocess
from anthropic import Anthropic
from rich.console import Console
from config.settings import ANTHROPIC_API_KEY, MANIM_MODEL
console = Console()
client = Anthropic(api_key=ANTHROPIC_API_KEY)
MANIM_SYSTEM_PROMPT = """Du bist ein Manim-Experte. Generiere für den gegebenen
Visual-Prompt eine vollständige Manim-Scene-Klasse die ChristianOhleScene heißt.
Constraints:
- from manim import *
- class ChristianOhleScene(Scene): mit construct(self) Methode
- Dauer in Sekunden ist gegeben - nutze entsprechende Wait()s und Animation-Längen
- Dunkler Hintergrund (BLACK), helle Objekte
- Keep it visually clean, kein Clutter
- KEINE imports außer manim, KEIN if __name__ block
"""
def generate_manim_code(visual_prompt: str, duration_sec: float) -> str:
"""Claude generiert Manim-Code für die Szene."""
user_msg = (
f"Visual-Prompt: {visual_prompt}\n\n"
f"Dauer: {duration_sec:.1f} Sekunden\n\n"
"Antworte AUSSCHLIESSLICH mit Python-Code, kein Markdown, keine Erklärungen."
)
resp = client.messages.create(
model=MANIM_MODEL,
max_tokens=8000, # KRITISCH: 3000 reicht nicht für komplexe Szenen!
system=MANIM_SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_msg}],
)
code = resp.content[0].text.strip()
if code.startswith("```"):
code = code.split("```")[1]
if code.startswith("python"):
code = code[6:].strip()
code = code.strip("`").strip()
return code
def render(visual_prompt: str, duration_sec: float,
output_dir: Path, scene_id: int) -> Path:
"""Generiere Manim-Code, render via subprocess, return final mp4."""
output_dir.mkdir(parents=True, exist_ok=True)
# 1. Code generieren
code = generate_manim_code(visual_prompt, duration_sec)
# 2. Code in Datei schreiben
code_file = output_dir / f"scene_{scene_id:03d}.py"
code_file.write_text(code, encoding="utf-8")
console.print(f"[dim]Manim-Code geschrieben: {code_file.name}[/dim]")
# 3. Manim-CLI aufrufen
console.print(f"[cyan]→ Manim render scene {scene_id}[/cyan]")
proc = subprocess.run(
["manim", "render", "-ql", str(code_file), "ChristianOhleScene"],
cwd=output_dir,
capture_output=True, text=True,
)
if proc.returncode != 0:
console.print("[red]Manim-Render fehlgeschlagen:[/red]")
console.print(proc.stderr[-2000:])
raise RuntimeError(f"Manim returncode {proc.returncode}")
# 4. Output-MP4 finden und in Pipeline-Format umbenennen
media_dir = output_dir / "media" / "videos" / f"scene_{scene_id:03d}" / "480p15"
rendered = next(media_dir.glob("*.mp4"))
target = output_dir / f"scene_{scene_id:03d}.mp4"
rendered.replace(target)
size_kb = target.stat().st_size // 1024
console.print(f"[green]✓ scene_{scene_id:03d}.mp4 ({size_kb} KB)[/green]")
return targetWie es funktioniert:
- Claude bekommt den
visual_promptaus dem Script-JSON („Schachbrett-Animation mit ELO-Kurve”). - Generiert Python-Code, der Manim-Scenes definiert.
- Code wird in
scene_NNN.pygeschrieben. manim render -ql scene_NNN.pyrendert das MP4.
Wichtige Lesson aus dem Build: max_tokens=3000 reicht nicht für komplexe Manim-Szenen. Mit 3000 Tokens hatte ich Syntax-Fehler, weil Claude mitten im Code abgeschnitten wurde. Mit 8000 Tokens läuft’s stabil. Das ist ein Detail, das in keinem Tutorial steht — kostete mich aber zwei kaputte Pipeline-Runs, bis ich es bemerkt hatte.
Der Slide-Renderer (Playwright)
Strategie: Claude generiert HTML mit Tailwind-Style aus dem visual_prompt. Playwright rendert das HTML in einem headless Chromium und macht einen Screenshot pro Frame, ffmpeg setzt die Frames zu einem MP4 zusammen.
Vorteile gegenüber direktem Bildgenerieren:
- Saubere Typografie
- Konsistentes Layout/Branding
- Schnell zu rendern
- Editierbar als HTML
Der ElevenLabs-Voice-Renderer
Standard-Setup mit eleven_multilingual_v2 für Deutsch. Voice-ID via .env konfigurierbar. Pro Szene wird der Voiceover-Text aus dem Scene-JSON in MP3 synthetisiert.
Aktuell läuft die Pipeline mit Standard-Voice. Plan ist Wechsel zu ElevenLabs Voice Cloning Deutsch mit eigener Stimme — braucht 30–60 Min Trainings-Audio, Setup dauert 1–2 Wochen serverseitig, bis ElevenLabs das Voice-Modell freischaltet.
Assembly mit ffmpeg + Whisper
Im Assembly-Code laufen folgende Schritte:
- Pro Szene: Visual-MP4 + Voiceover-MP3 zusammenmergen, Visual auf Audio-Länge stretchen/loopen.
- Alle Szenen-Clips concatten zu
master.mp4. - BGM mixen (optional, Pfad in
data/assets/bgm.mp3). - Whisper transkribiert den Audio-Track, schreibt SRT.
- Final-MP4 in
data/output/<topic_id>.mp4.
Wichtiger Windows-Fix: ffmpegs subtitles=-Filter hasst Windows-Pfade mit : und \. Workaround: ins SRT-Verzeichnis cd-en und nur den Filename übergeben.
import os
cwd = os.getcwd()
try:
os.chdir(srt_file.parent)
cmd = ["ffmpeg", "-y", "-i", str(video),
"-vf", f"subtitles={srt_file.name}:force_style='{style}'",
...]
_run(cmd)
finally:
os.chdir(cwd)Pipeline-Orchestrierung mit Caching und Error-Handling
Im Pipeline-Orchestrator laufen zwei kritische Patches, die im Production-Run unverzichtbar waren:
"""Pipeline-Orchestrator: Topic → fertiges MP4.
Patches die im Production-Run unverzichtbar waren:
1. Cache-Logik: existierende Renders werden übersprungen
2. Fallback statt Crash: kaputte Manim-Szenen → Slide-Renderer
"""
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
from rich.console import Console
from src.script.schema import VideoScript, Scene
from src.visual.manim import renderer as manim_r
from src.visual.slide import renderer as slide_r
from src.visual.stock import renderer as stock_r
from src.visual.comfy import renderer as comfy_r
from src.voice import tts
from src.assembly import build as asm
from config.settings import RAW_DIR, ensure_dirs
console = Console()
def _render_scene(scene: Scene, raw_dir: Path) -> Path:
"""Dispatch auf den richtigen Renderer mit Cache-Check."""
sub = raw_dir / scene.visual_type
# PATCH 1: Cache-Hit für bereits gerenderte Szenen
cached = sub / f"scene_{scene.scene_id:03d}.mp4"
if cached.exists() and cached.stat().st_size > 1024:
console.print(f"[dim]Cache hit: scene_{scene.scene_id:03d} ({scene.visual_type})[/]")
return cached
if scene.visual_type == "manim":
return manim_r.render(scene.visual_prompt, scene.duration_sec, sub, scene.scene_id)
if scene.visual_type in ("slide", "title_card"):
prompt = scene.visual_prompt
if scene.visual_type == "title_card":
prompt = f"BULLETS-Layout mit nur dem Titel als h1: {prompt}"
return slide_r.render(prompt, scene.duration_sec, sub, scene.scene_id)
if scene.visual_type == "stock":
return stock_r.fetch_clip(scene.visual_prompt, sub, scene.scene_id, scene.duration_sec)
if scene.visual_type == "comfy":
return comfy_r.render(scene.visual_prompt, scene.motion_hint, scene.duration_sec, sub, scene.scene_id)
raise ValueError(f"Unbekannter visual_type: {scene.visual_type}")
def run(script_path: Path, parallel_visuals: int = 2) -> Path:
ensure_dirs()
script = VideoScript.model_validate_json(script_path.read_text(encoding="utf-8"))
topic_id = script.topic_id
raw = RAW_DIR / topic_id
raw.mkdir(parents=True, exist_ok=True)
visual_paths: dict[int, Path] = {}
gpu_scenes = [s for s in script.scenes if s.visual_type == "comfy"]
other_scenes = [s for s in script.scenes if s.visual_type != "comfy"]
# Parallel rendern (außer Comfy/Replicate)
with ThreadPoolExecutor(max_workers=parallel_visuals) as ex:
futures = {ex.submit(_render_scene, s, raw): s for s in other_scenes}
for fut in as_completed(futures):
s = futures[fut]
try:
visual_paths[s.scene_id] = fut.result()
except Exception as e:
# PATCH 2: Fallback auf Slide-Renderer statt Pipeline-Abbruch
console.print(f"[red]Scene {s.scene_id} ({s.visual_type}) failed: {e}[/]")
console.print(f"[yellow] Fallback auf Slide-Renderer für Scene {s.scene_id}[/]")
fallback_sub = raw / "slide"
visual_paths[s.scene_id] = slide_r.render(
s.visual_prompt, s.duration_sec, fallback_sub, s.scene_id
)
# Comfy/Replicate seriell (rate-limit-bewusst)
if gpu_scenes:
for s in gpu_scenes:
visual_paths[s.scene_id] = _render_scene(s, raw)
# Voiceover seriell
audio_dir = raw / "voiceover"
audio_paths = tts.synthesize_scenes(script.scenes, audio_dir)
audio_map = {s.scene_id: p for s, p in zip(script.scenes, audio_paths)}
# Assembly: visual + audio in Render-Reihenfolge
pairs = [(visual_paths[s.scene_id], audio_map[s.scene_id]) for s in script.scenes]
final = asm.build(topic_id, pairs)
return finalPatch 1 — Cache-Logik in _render_scene: Wenn eine Szene schon gerendert wurde, skip. Sonst rendert die Pipeline bei jedem Re-Run alle 14 Szenen neu, was bei einem Crash in Szene 12 sehr teuer ist. Der Check ist simpel: existiert die Ziel-Datei, ist sie größer als 1 KB? Cache-Hit. Das spart bei jedem Re-Run minutenlang Rechenzeit.
Patch 2 — Fallback statt Crash: Wenn ein Manim-Renderer fehlschlägt (Claude generiert mal kaputten Code), nicht die ganze Pipeline killen. Stattdessen: auf Slide-Renderer fallen und weiter. Die Pipeline ist damit robust gegen einzelne Render-Fehler — und weil Slide auch via Claude-Generation läuft, ist die Qualität meist akzeptabel.
Production-Run — die David-Silver-Story
Erster vollständiger Pipeline-Run zum Test.
Topic (von News-Scraper geliefert):
„DeepMind’s David Silver raised $1.1B to build AI that learns without human data”
Generiertes Script (Claude Opus 4.7):
- Titel: „1,1 Mrd. Dollar für KI ohne Menschen-Daten — Silvers Wette”
- 14 Szenen, ~256 Sekunden Sprechdauer
- Visual-Mix: 8× Manim, 5× Slide, 2× Comfy/Replicate, 1× Title-Card
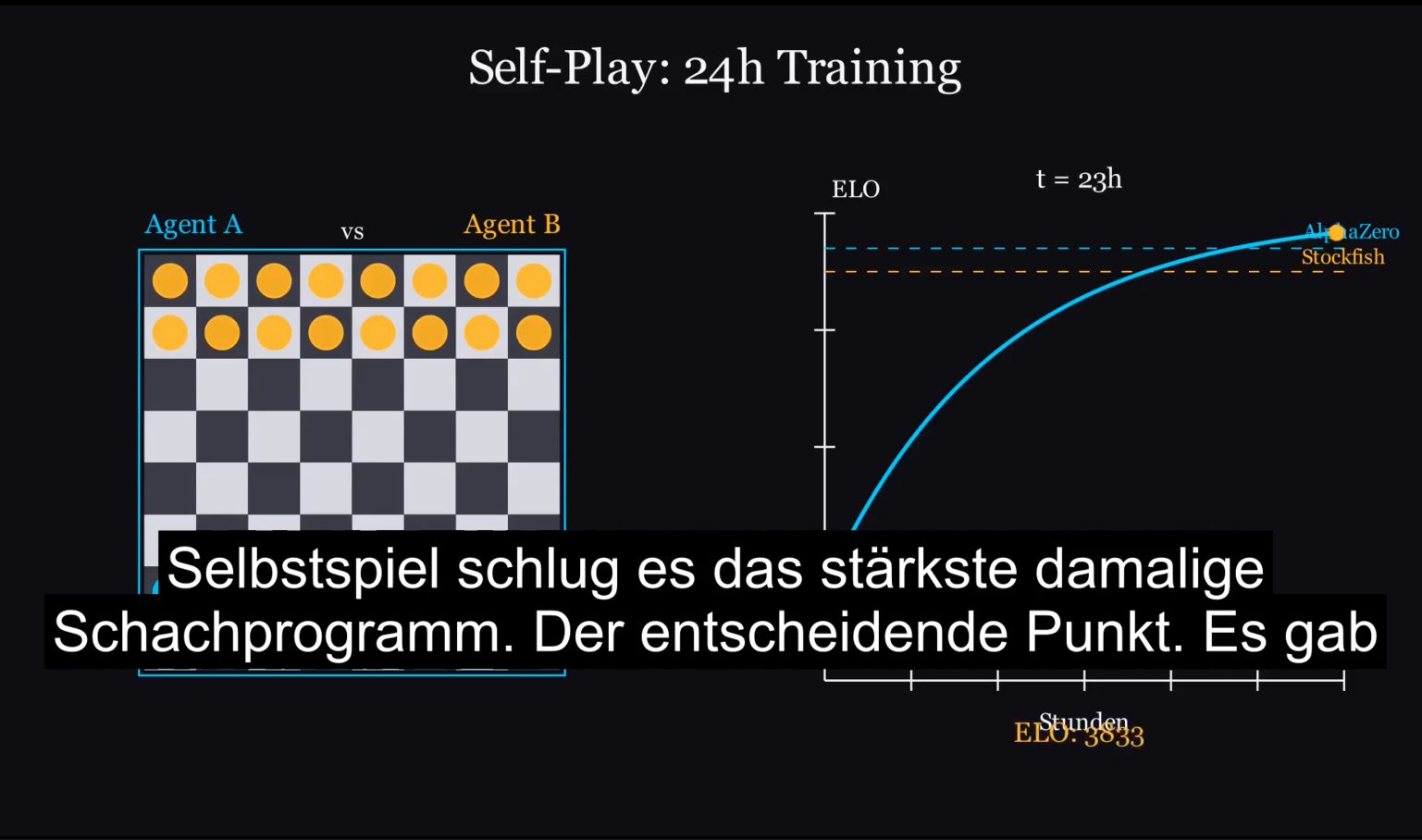 Eine der finalen Manim-Szenen aus dem Test-Video: Self-Play-Training mit ELO-Kurve, automatisch generiert aus dem Visual-Prompt im Script-JSON.
Eine der finalen Manim-Szenen aus dem Test-Video: Self-Play-Training mit ELO-Kurve, automatisch generiert aus dem Visual-Prompt im Script-JSON.
Render-Zeiten:
- Manim parallel: ~12 Min für 8 Szenen (2 Worker)
- Slide parallel: ~5 Min für 5 Szenen
- Replicate Comfy seriell: ~1 Min für 2 Szenen
- ElevenLabs TTS seriell: ~3 Min für 14 Szenen
- Assembly + Whisper: ~5 Min
Total: ~25 Minuten für ein 4:30-Minuten-Video.
Kosten:
- Claude API (Script + Manim-Code + Slide-HTML): ~$0.40
- Replicate (2 Bilder Flux Schnell): ~$0.01
- ElevenLabs (14 Szenen DE): ~$0.50
- Total: ~$0.91 pro Video
Bei 12 Videos pro Monat: ~$11/Monat operative Kosten. Plus Anthropic-Plan und ElevenLabs-Sub. Eine YouTube Automation Pipeline 2026 auf diesem Stand ist betriebswirtschaftlich kein Thema mehr — der größte Kostenblock ist mein Stundensatz für Topic-Auswahl und Review, nicht die API-Calls.
Was ich gelernt habe
1. AMD ROCm Windows ist 2026 noch nicht produktionsreif für I2V. Für T2I in einfachen Workflows läuft es. Für Memory-Heavy I2V crasht es. Wenn du eine Pipeline brauchst, die zuverlässig durchläuft, ist Cloud-API der pragmatische Weg — auch wenn das ideologisch unbefriedigend ist.
2. Pivots sind Erfolg, kein Scheitern. Mein ursprünglicher Plan (alles lokal) ist nicht aufgegangen. Der finale Stack (Hybrid lokal+Cloud) ist besser als der Originalplan — stabiler, schneller, fast genauso günstig. Wer einen faceless YouTube Channel automatisieren will, sollte nicht stur am ersten Architekturentwurf festhalten.
3. Templates sind Tradeoffs. „SDXL Simple” mit Base+Refiner sieht harmlos aus, aber halbe Modifikationen führen zu still failing Output. Lieber Minimal-Workflow von Hand bauen als Refiner-Templates „vereinfachen”.
4. Caching und Error-Handling sind nicht optional. Eine Pipeline, die bei einem einzigen Fehler abbricht, ist im Production-Use unbrauchbar. Cache + Fallback retten Stunden, jedes Mal wenn ein einzelner Render-Step zickt.
5. Manim ist der Differenzierer im DACH-KI-Niche. Während alle anderen Stock-Footage und KI-Bilder reincutten, kannst du mit Manim mathematische Konzepte sauber visualisieren. Das ist 3Blue1Brown-Territorium — und in deutscher Sprache mit KI-Fokus völlig unbesetzt.
Das fertige Video
Das Resultat dieser Pipeline: ein 4:30-Minuten-Video über David Silvers $1.1B Funding für menschen-data-freie KI — komplett automatisch gerendert.
<!-- YouTube-Embed wird hier eingebunden, sobald veröffentlicht -->
<div class="video-container">
<iframe src="https://www.youtube.com/embed/VIDEO_ID"
allowfullscreen></iframe>
</div>FAQ — Häufige Fragen zur Pipeline
Was ist ein faceless YouTube Channel?
Ein faceless YouTube Channel produziert Videos, ohne dass der Creator vor der Kamera steht. Stattdessen werden Voiceover, Stock-Footage, Animationen und KI-generierte Visuals genutzt. Der Vorteil: höhere Skalierbarkeit, weniger Production-Aufwand, Anonymität. Faceless-Channels in den Niches Finance, Tech und Productivity gehören zu den umsatzstärksten Formaten 2026.
Was kostet eine faceless YouTube Pipeline?
Eine self-hosted Pipeline kostet ~$1 pro Video an API-Calls (Claude, Replicate, ElevenLabs). Plus Anthropic-Plan ($20/Monat) und ElevenLabs-Subscription ($5–22/Monat). All-in-One-SaaS-Tools wie FluxNote oder Clippie liegen bei $19–39/Monat. Bei mehr als 20 Videos/Monat ist Self-Hosting deutlich günstiger.
Welche AI-Tools brauche ich für einen automatisierten YouTube Channel?
Minimum-Stack: ein LLM für Scripts (Claude oder GPT), ein TTS-Tool (ElevenLabs für höchste Qualität), eine Visual-Source (Replicate Flux für Bilder, Manim für Animationen, Pexels für Stock) und ffmpeg für Assembly. Optional: Whisper für automatische Untertitel, Playwright für HTML-basierte Slides.
Funktioniert ComfyUI auf AMD GPUs?
ComfyUI funktioniert grundsätzlich auf AMD GPUs mit ROCm. Stand 2026 ist die Stabilität auf Windows aber problematisch, besonders bei Memory-Heavy I2V-Modellen wie Wan 2.2 oder LTX. Bekannte Probleme: HIP errors, illegal memory access, System-Crashes. Für T2I-Workflows in einfacher Form ist es brauchbar. Für Production-Pipelines aktuell nicht zuverlässig.
Was ist Manim und warum ist es relevant für KI-Videos?
Manim ist eine Python-Library für mathematische Animationen, ursprünglich von 3Blue1Brown entwickelt. Für KI-Erklärvideos ist Manim relevant, weil es konzeptionelle Animationen (Vektoren, Graphen, Transformationen) sauber visualisiert. Im Gegensatz zu generierten KI-Videos sind Manim-Animationen reproduzierbar, präzise und perfekt für komplexe technische Themen.
Wie lange dauert die Produktion eines KI-generierten YouTube-Videos?
Mit einer vollautomatischen Pipeline: 25–30 Minuten für ein 4–7 Minuten Video. Ohne Automatisierung 6–8 Stunden manuell. Die Pipeline läuft headless — während sie rendert, kann der Creator anderen Aufgaben nachgehen. Tatsächlicher menschlicher Input: Topic-Auswahl, finale Review, Upload-Strategy.
Wie monetarisiert man einen faceless YouTube Channel?
Hauptkanäle: AdSense (1.000 Subscriber + 4.000 Watch-Hours notwendig), Affiliate-Marketing in Video-Beschreibungen, Sponsoring nach Channel-Wachstum. RPM (Revenue per Mille) variiert stark nach Niche: Finance/Tech bis $20 pro 1.000 Views, generische Themen unter $3. Faceless-Channels mit 100k Monthly Views erreichen typischerweise $200–2.000 monatlichen Umsatz.
Fazit
Eine vollautomatische YouTube-Pipeline zu bauen ist 2026 keine Nische-Engineering-Disziplin mehr. Die Bausteine — Claude für Scripts und Code-Gen, Replicate für Bilder, Manim für Animationen, ElevenLabs für Voiceover, ffmpeg + Whisper für Assembly — sind reif, dokumentiert und bezahlbar. Was den Unterschied macht, ist die Orchestrierung: Cache, Fallbacks, sinnvolle Parallelisierung, klares Schema zwischen den Stages.
Was nicht funktioniert hat — lokales I2V auf AMD ROCm — habe ich nicht versteckt. Das ist Stand 2026 die Realität, und wer es trotzdem versuchen will, soll es wenigstens mit offenen Augen tun. Der Pivot auf Replicate Flux Schnell + Ken-Burns hat die Pipeline rettungslos rettungsreich gemacht: stabil, schnell, ~$0.91 pro Video.
Wenn du den Stack nachbauen willst: das komplette Repo gibt’s auf github.com/christianohle (in Arbeit). Den Channel selbst findest du auf YouTube — christian-ohle, sobald die ersten Videos live sind. Wer wissen will, wie ich den Stack weiterentwickle — Voice-Cloning-Setup, A/B-Tests bei Topic-Selection, Brevo-Integration für Newsletter — der Newsletter hat alle 1–2 Wochen ein Update.
Vertiefend: MCP Server bauen zeigt, wie du eigene Tool-Integrationen für Claude baust, die du auch aus so einer Pipeline aufrufen kannst. KI-Automatisierung mit eigenen Pipelines gibt den allgemeineren Architektur-Überblick — wann lohnt No-Code, wann Hybrid, wann Full-Code. Im Tools-Verzeichnis findest du Replicate, Claude, ElevenLabs und ffmpeg mit aktueller DSGVO-Bewertung.
Quellen
- Replicate — Flux Schnell Modell
- Manim Community Documentation
- ElevenLabs Text-to-Speech API
- Anthropic Claude API Documentation
- FFmpeg Documentation
- OpenAI Whisper auf GitHub



